In this post, I shall reveal an algorithm that generates all possible combinations of a given set of characters of a specified range of lengths. The algorithm is as follows:
1. take dict as a character array of possible characters in your string combinations
take currLen as integer, startLen as integer, stopLen as integer, chars as character array, indices as integer array
2. initialize currLen = startLen
3. Set length of chars array to currLen, length of indices array to currLen
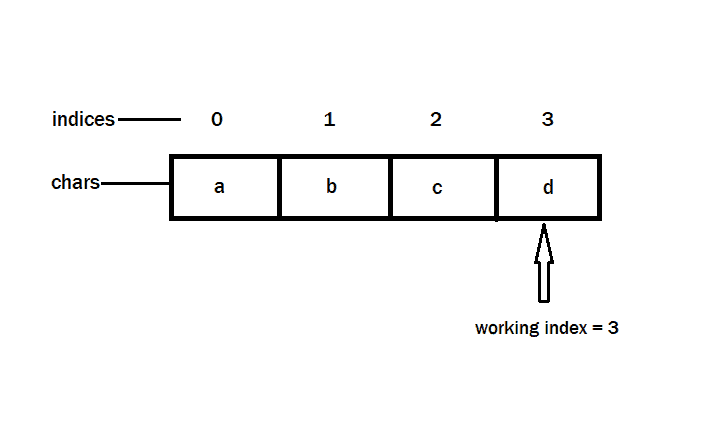
4. set working_index = currLen - 1
5. get string from chars array as follows
i. set i'th element of chars array to indices[i]'th element of dict
ii. Do the operation in the previous step (i) from i = 0 to i = currLen - 1
iii. concatenate the elements of chars array to generate a string combination of characters
6. print string in step 5
7. if all elements of indices equal length of dict - 1
if currLen < stopLen
increment currLen by 1
go to step 3
else
quit
8. if element of indices at position = working_index < length of dict - 1
increment element of indices at position = working_index by 1
go to Step 5
else
if currLen > 1
decrement working_index by 1 till element of
indices at position = working_index equals length of dict - 1
if working_index equals -1
if currLen < stopLen
increment currLen by 1
go to Step 3
else
quit
else
increment element of indices at position = working_index by 1
set all elements of indices to the right of position = working_index to 0
go to Step 4
else
if currLen < stopLen
increment currLen by 1
go to Step 3
else
quit
At first glance, this algorithm may look like a brute force algorithm, but I seriously doubt that it can be used to do naughty things like cracking passwords. Of course, to unleash the full power of this algorithm, one needs to parallelize the code in his implementation of this algorithm. That way we can max out the cpu cores and enjoy a very large number of iterations per second.
It may, however, be used to create a reverse lookup database of one way cryptographic hash functions. But, with the use of salts being common nowadays, such a database of all possible plaintexts and their hashes may not be useful after all.
The best part about this algorithm is that it is non-recursive and so avoids an inordinately large number of function calls and a potential call stack overflow. This is true especially when the dictionary of characters is very large.
So, all in all, this algorithm may be used as a fun academic exercise. Or, perhaps one of you guys may come up with a practical use for this algorithm.